|
|
[md]
(为什么知乎自动转换的 markdown 会多出来空行……)
来晚了,不过我是带着干货来的。
本回答将为大家解释*真实*的原因,我认为是比大家的各种猜测要更真实一些的。
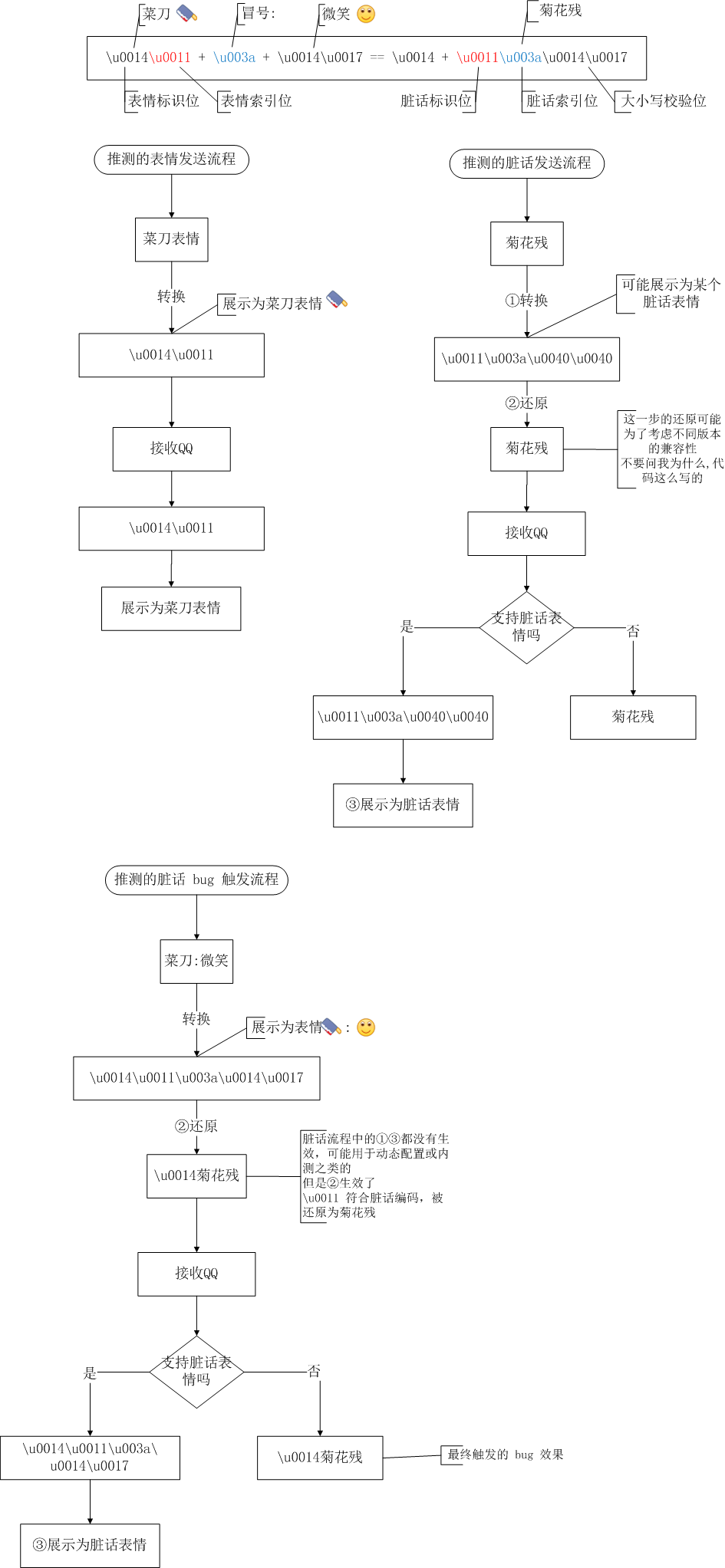
# 0x00 先上结论
## 0.1 真实原因:
1. QQ 使用 \u0014 加 1 个字符(该字符为表情序号)表示表情
2. QQ 使用 \u0011 加 3 个字符表示脏话
3. 当 \u0014 与 \u0011 再与别的 3 个字符组合到一起,就出现了问题,虽然输入的是表情,却被处理为脏话
4. 而 \u0014\u0011 表示的表情为第 0x11 个,即第 17 个表情
而第 17 个表情,它就是天选之表情,脏话 bug 幕后元凶,知乎话题缔造者,程序猿背锅原因!
菜刀!!!
看到有不少朋友还是不明白 bug 是如何产生的,笔者再补一张*推测*的流程图。
写这个回答只是为了解答笔者心中的为什么,分析完之后笔者已经没有为什么了(其实还有,无伤大雅)。
如果朋友们还有为什么,可以自行查看源码分析,请不要杠笔者,笔者好无辜啊。
表情序号部分相关源码
com.tencent.mobileqq.text.EmotcationConstants
static{
...
String[] v0 = new String[203];
v0[0] = "/呲牙";
v0[1] = "/调皮";
v0[v9] = "/流汗";
v0[v11] = "/偷笑";
v0[4] = "/再见";
v0[5] = "/敲打";
v0[6] = "/擦汗";
v0[7] = "/猪头";
v0[8] = "/玫瑰";
v0[9] = "/流泪";
v0[10] = "/大哭";
v0[11] = "/嘘...";
v0[12] = "/酷";
v0[13] = "/抓狂";
v0[14] = "/委屈";
v0[15] = "/便便";
v0[16] = "/炸弹";
v0[17] = "/菜刀";
...
}
## 0.2 验证方式
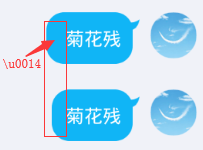
截图中可以看到转义过的“菊花残”比正常的“菊花残”前面好像多了一点空白。
多出的空白就是无法显示的 \u0014
将 QQ 消息复制出来,粘帖到 idea 的双引号中,就会自动转义为 \u 形式
public void test() {
//菜刀表情
String a = "\u0014\u0011";
//菜刀表情+冒号+微笑表情
String b = "\u0014\u0011:\u0014\u0017";
//发出去之后变成的 菊花残
String c = "\u0014菊花残";
//可以看到 \u0011:\u0014\u0017 被还原为了 菊花残
}
## 0.3 脏话的处理逻辑是什么
为什么点击发送的时候,要将处理过的脏话还原呢?
经过*推测*,应该是这样的逻辑。
1. 在输入时,监听 afterTextChanged 将输入的脏话转义
2. 在发送时,将已转义过的脏话还原,发送给服务器
(可能为了保证不同版本发送消息的准确,比如转义只存在于 Android ,为了低版本或别的版本正常显示,只能发送未转义的内容)
3. 在收到消息时,再将收到脏话转义
每一个步骤都受变量或方法控制,为 true 才执行相关步骤。
虽然步骤 1 和 3 没有执行,但是步骤 2 却执行了。
按理说没有执行 1 的转义,执行 2 的还原也没有影响,但是却遇到了菜刀的 \u0011,触发了 bug。
前面说的好像很有道理,为什么要说是“推测”呢,因为控制 1 和 3 变量,在代码中的确是 true,但实际却没有执行。
一定是我阅读代码的方式不对,留待以后 QQ 更新版本验证或等大神指点。
# 0x01 分析过程
## 1.1 好奇心
知乎上给推送了相关问题,很感兴趣,然后有网友反编译了代码,但是只能说明在代码里存在脏话,并不能解释**为什么**?
尤其是为什么 菜刀+字符 就会显示,会什么别的表情不会?
有网友推测是写反了,如果是这样,为什么会过得了测试和代码 review?
为什么要把脏话替换为 菜刀加其他?
这显然是不能满足我的好奇心。
后文即整个分析过程,仅用于学习交流,侵删。
简单分析,有不对的地方欢迎指正。
原文地址[[2538]QQ 发送菜刀加符号导致脏话的真实原因分析](https://www.pingfangx.com/blog/2538)
## 1.2 LoveLanguageManager 中与脏话相关的方法
根据之前网友的反编译的结果,我们找到 classes2.dex 中的包 com.tencent.mobileqq.lovelanguage
经过一番查看,我们在 LoveLanguageManager 中找到两个可疑方法,分别用于将 EditText 中的脏话进行替换与还原
**(后文中的代码,都可能经过了笔者的重命名与注释,并非原始代码)**
public int a(EditText editText) { // 将脏话还原
int v10 = 2;
this.d = false;
String text = editText.getText().toString();
long v6 = System.currentTimeMillis();
int textLength = text.length();
int v0 = 0;
int v3 = 0;
while(v0 < textLength) {
if(text.charAt(v0) == 17 && v0 < textLength - 3 && (LoveLanguageConfig.a(text.charAt(v0 + 1)))) {
textLength = v0 + 4;
String v5 = LoveLanguageConfig.a(text.substring(v0, textLength));
editText.getEditableText().replace(v0, textLength, ((CharSequence)v5));
text = editText.getText().toString();
textLength = text.length();
v0 = v0 + v5.length() - 1;
++v3;
}
++v0;
}
this.d = true;
...
this.a();
return v3;
}
public void a(EditText editText) { // 将脏话替换
String v6_1;
int v4;
int v2;
if((this.d) && editText != null) {
String text = editText.getText().toString();
if(!TextUtils.isEmpty(((CharSequence)text))) {
this.d = false;
int textLength = text.length();
int replaceCount = 0;
long startTime = System.currentTimeMillis();
int v3 = -1;
int searchIndex = 0;
while(searchIndex < textLength) {
if(text.charAt(searchIndex) != 17) {
if(replaceCount < 20) {
for(v2 = 0; v2 < LoveLanguageConfig.badWordsArray.length; ++v2) {
String badWords = LoveLanguageConfig.badWordsArray[v2];
int badWordsEnd = badWords.length() + searchIndex;
if(badWordsEnd <= textLength) {
String v12 = text.substring(searchIndex, badWordsEnd);
if(badWords.equals(v12.toLowerCase())) {
int v13 = editText.getSelectionEnd();
String replaceWord = LoveLanguageConfig.a(v2, v12);
editText.getEditableText().replace(searchIndex, badWordsEnd, ((CharSequence)replaceWord)); // 替换
text = editText.getText().toString();
textLength = text.length();
if(QLog.isColorLevel()) {
QLog.d("LoveLanguageManager", 2, new Object[]{"love language handleLoveLanguageConvert = ", v12, ",code=", Integer.valueOf(replaceWord.charAt(1)), ",pos1=", Integer.valueOf(replaceWord.charAt(2)), ",pos2=", Integer.valueOf(replaceWord.charAt(3))});
}
// 后面的代码有点乱,可能是因为反编译的原因;其逻辑就是设置 searchIndex,replaceCount 等
...
}
}
}
}
v2 = searchIndex;
v4 = replaceCount;
searchIndex = textLength;
v6_1 = text;
}
else if(replaceCount >= 20) {
...
}
else {
...
}
...
this.d = true;
}
}
}
由于反编译的效果不理想,只要简单知道,它们分别调用了 LoveLanguageConfig 中的相关方法
## 1.3 LoveLanguageConfig 中脏话的替换与还原方法
public static String a(int index, String text) { // 替换脏话
int v3;
int v2;
int v0 = 64;
// 这里应该是 || 反编译的问题
if(index < 0 && index >= LoveLanguageConfig.a.length) {
throw new IllegalArgumentException("love language invalid index: " + index);
}
// 0-5,26,27 这几个在 badWordsArray 中是英文,单独进行了处理,用来标识字母大小写
if(index >= 0 && index <= 5 || (index == 26 || index == 27)) {
v2 = v0;
v3 = v0;
for(v0 = 0; v0 < text.length(); ++v0) {
if(Character.isUpperCase(text.charAt(v0))) {
if(v0 < 6) {
v3 |= 1 << 6 - v0 - 1;
}
else {
v2 |= 1 << 12 - v0 - 1;
}
}
}
}
else {
v2 = v0;
v3 = v0;
}
// 这里我们看出第 0 位用来作脏话标识 \u0011 即 17;第 1 位用来标识 index
return String.valueOf(new char[]{'\u0011', ((char)LoveLanguageConfig.a(index)), ((char)v3), ((char)v2)});
}
public static String a(String arg8) { // 还原出脏话
String v0_1;
int v1;
int v0 = LoveLanguageConfig.a(arg8.charAt(1));
String v2 = LoveLanguageConfig.badWordsArray[v0];
int v3 = arg8.charAt(2);
int v4 = arg8.charAt(3);
StringBuilder v5 = new StringBuilder(10);
if(v0 >= 0 && v0 <= 5 || (v0 == 26 || v0 == 27)) {
for(v0 = 0; v0 < v2.length(); ++v0) {
if(v0 < 6) {
v1 = 6 - v0 - 1;
v1 = (1 << v1 & v3) >> v1;
}
else {
v1 = 12 - v0 - 1;
v1 = (1 << v1 & v4) >> v1;
}
char v1_1 = v1 == 1 ? ((char)(v2.charAt(v0) - 32)) : v2.charAt(v0);
v5.append(v1_1);
}
v0_1 = v5.toString();
}
else {
v0_1 = v2;
}
return v0_1;
}
public static boolean a(char arg1) {
boolean v0 = arg1 < 30 || arg1 >= LoveLanguageConfig.badWordsArray.length + 30 ? false : true;
return v0;
}
public static boolean a(String arg3) {
boolean v0 = false;
// 这个方法可能是用业判断是否包含转义过的脏话,判断包启 17
if(!TextUtils.isEmpty(((CharSequence)arg3)) && -1 != arg3.indexOf(17)) {
v0 = true;
}
return v0;
}
## 1.4 发送消息时是否调用了相关方法
那么发送消息的时候,是否调用了将脏话还原的方法呢?为什么要调用呢?
我们直接搜索 `Lcom/tencent/mobileqq/lovelanguage/LoveLanguageManager;->a(Landroid/widget/EditText;)`
共有 3 处调用
classes3\com\tencent\mobileqq\apollo\ApolloPanelManager
这个阿波罗不知道是干什么的。
classes6\com\tencent\mobileqq\activity\BaseChatPie
在 BaseChatPie 中,afterTextChanged
((LoveLanguageManager)v0).a(this.a);
label_228:
if(QLog.isColorLevel()) {
QLog.d("afterTextChanged", v10, " afterTextChanged cost: " + (System.currentTimeMillis() - v6));
}
在 al() 中
int v8 = LoveLanguageConfig.a(this.a.getText().toString()) ? this.a.getManager(273).a(this.a) : 0;
if(QLog.isColorLevel()) {
QLog.d("SendMsgBtn", 2, " send curType == VALUE.UIN_TYPE_TROOP or disc start sendMessage currenttime:" + System.currentTimeMillis());
}
配合 log 中的文字,我们知道,似乎是要在文字输入后,就将脏话替换
但是在点击发送时,要将处理过的脏话还原出来(不知因为某些原因需要还原)
这里就是问题所在,其实输入的内容中并没有处理过的脏话,只有表情,但是却把表情错误的还原了。
## 1.5 官方补丁验证猜想
后来官方怎么修复的呢,我们发现了一个补丁: patch_2018-05-28_22_06_release.dex
这个补丁只改了两个类
com.tencent.mobileqq.app.asyncdb.cache.RecentUserCache
com.tencent.mobileqq.lovelanguage.LoveLanguageManager
而 LoveLanguageManager 只改了一个方法
public int a(EditText arg11) { // 补丁
int v9 = 2;
this.d = false;
String v0 = arg11.getText().toString();
long v2 = System.currentTimeMillis();
this.d = true;
if(QLog.isColorLevel()) {
Object[] v4 = new Object[6];
v4[0] = "love language handleLoveLanguageRevert count = ";
v4[1] = Integer.valueOf(0);
v4[v9] = ",cost =";
v4[3] = Long.valueOf(Math.abs(System.currentTimeMillis() - v2));
v4[4] = ",send:";
v4[5] = v0;
QLog.d("LoveLanguageManager", v9, v4);
}
this.a();
return 0;
}
我们看到,直接将该脏话还原方法中的逻辑去掉了。
## 1.6 表情是如何被错误还原的
一开始我猜想,是不是因为菜刀在 QQ 中表现为“/cd” 或者是“/菜刀”中包含了 \u0011,所以触发了 bug,查看发现不是。
后来直接查看 QQ 的聊天记录数据库,发现保存的菜刀为"\u0014\u0011",果然如此,问题解决。
菜刀表情以 \u0011 结尾,配合后面 3 个字符,正好以符合脏话的转义规则,被错误地还原为脏话。
后来发现将字符复制到 idea 中 双引号中,会自动用 \u 转义
后续在 com.tencent.mobileqq.text.EmotcationConstants 中证实了对表情的处理,菜刀确实是第 17 个,即 \u0014\u0011
## 1.7 整理前文推测的 3 个步骤
1. 输入时替换
classes6\com\tencent\mobileqq\activity\BaseChatPie#afterTextChanged
2. 发送时还原
classes6\com\tencent\mobileqq\activity\BaseChatPie#al
3. 收到消息后转义,使用的转义方法为
Lcom/tencent/mobileqq/lovelanguage/LoveLanguageManager;->a(Ljava/lang/String;)Ljava/lang/String;
调用处有
classes\com\tencent\mobileqq\app\message\BaseMessageManager
classes4\com\tencent\mobileqq\data\MessageForText
classes6\com\tencent\mobileqq\activity\ChatHistory$ChatHistoryAdapter
# 0x02 后续
## 2.1 这个 bug 为什么会被发现?
菜刀表情加符号加其他,好像并不难触发
## 2.2 别的表情能触发吗?
不能,前面分析说了,必须是第 17 个表情,在 1.6 中已经显示,该表情为菜刀。
## 2.3 不用表情可以触发吗?
能,前面分析了,只要是 \u0011 加一个字符表示脏话序号,加 2 个字符用于大小写校验。
比如一开始的 菜刀表情+冒号+微笑表情,实际为 \u0014\u0011:\u0014\u0017(冒号为 58 即 3a)
实际用于转义脏话的内容可以为 \u0011\u003a\u0040\u0040 修改第 2 个字符就会被转义为其他脏话
测试的时候发现 \u0011\u003a 被转义为一个高尔夫球进洞的表情,好像与 2.2 中的结论冲突……
## 2.4 菜刀表情+冒号+微笑表情 是如何被转义的菊花残的
static {
//脏话列表
LoveLanguageConfig.badWordsArray = new String[]{"asshole", "bitch", "damn you", "fuck", "go to hell", "shit", "爆菊", "碧莲", "婊子", "草泥马", "尼玛", "丢你老母", "法克鱿", "狗屁", "滚蛋", "绿茶婊", "去你大爷", "去你妈的", "我去你妹", "死胖子", "日你妈", "弱智", "他妈的", "王八蛋", "我靠", "猪一样", "fatty", "idiot", "菊花残", "没屁眼", "臭婊砸", "贱逼", "该死的", "操你", "去死吧", "白痴", "傻瓜", "痴线", "傻屌", "傻逼", "吃屎", "捅你菊花", "插你菊花", "屁眼交易", "卧槽", "我操", "丢雷老母", "狗屎", "混蛋", "操蛋", "妈蛋", "老不死", "你妈逼", "干你妹的", "操你妹的", "表要脸", "去他喵的", "龟儿子", "老王八", "龟孙", "我日", "狗日的", "猪脑", "猪头", "心机婊", "我草", "脑残"};
//这个数组按理说是用来标识 index ,但是实际代码中只是使用了 index+30 作为标识
LoveLanguageConfig.a = new int[]{2130839308, 2130839309, 2130839320, 2130839327, 2130839328, 2130839329, 2130839330, 2130839331, 2130839332, 2130839333, 2130839333, 2130839311, 2130839312, 2130839313, 2130839314, 2130839315, 2130839316, 2130839317, 2130839318, 2130839319, 2130839321, 2130839322, 2130839323, 2130839324, 2130839325, 2130839326, 2130839319, 2130839322, 2130839308, 2130839308, 2130839309, 2130839309, 2130839320, 2130839327, 2130839328, 2130839322, 2130839322, 2130839322, 2130839322, 2130839322, 2130839329, 2130839330, 2130839330, 2130839330, 2130839310, 2130839310, 2130839311, 2130839313, 2130839314, 2130839314, 2130839314, 2130839316, 2130839317, 2130839318, 2130839318, 2130839332, 2130839323, 2130839324, 2130839324, 2130839324, 2130839321, 2130839321, 2130839326, 2130839326, 2130839315, 2130839310, 2130839322};
}
public static int a(char arg1) {
return arg1 - 30;
}
public static int a(int arg1) {
return arg1 + 30;
}
冒号是 58,58-30=28,脏话数组中 index 为 28 的正好是“菊花残”
所以为什么网友会试出很多脏话,因为不同的字符对应不同的编码,其减去 30 就为 index,index 对应不同的脏话。
## 2.5 bug 完全修复了吗?
没有,当时笔者猜想,这是客户端的 bug,不可能通过服务器的限制进行修复。
后来官方也只是发布了一个补丁(patch_2018-05-28_22_06_release.dex),如果清空数据,这个补丁就没了,bug 复现。
在 v7.6.3.3560 版本中存在该 bug
## 2.6 为什么要转义脏话?
参照电脑 QQ 的快捷表情功能
输入 /cd 会被转换为菜刀表情,而菜刀表情实际为 \u0014\u0011。
脏话也应该是一样的逻辑,你输入脏话,就给你转换为 \u0011+其他字符,后续 \u0011 在显示时可以展示为不同的表情。
测试任务见网友这张图。

## 2.7 作者分析这么多有什么用
没什么用呀,只是终于能解释我心中的为什么了,没准这个回答也可以用来回答那个问题“你见过的什么什么 bug”[/md] |
|
 |小黑屋|手机版|Archiver|平方X
( 冀ICP备14018164号 )
|小黑屋|手机版|Archiver|平方X
( 冀ICP备14018164号 )







 发表于 2018-5-30 18:26:07
发表于 2018-5-30 18:26:07